개인정보보호위원회(이하 개인정보위)가 생성형 인공지능(AI)을 개발하거나 활용하는 기업과 기관을 위한 개인정보 처리 안내서를 6일 공식 공개했다.
이 안내서는 생성형 AI 서비스의 기획부터 운영까지 전 과정에서 개인정보 보호법의 적용 기준을 구체적으로 제시해, 법 적용의 불확실성을 줄이는 동시에 기업의 자율적인 법 준수 역량을 높이는 데 목적이 있다.
이번 안내서는 특히 챗GPT와 같은 상용 거대언어모델(LLM) 서비스뿐만 아니라, 메타가 제공한 오픈소스 모델인 '라마(LLaMA)'처럼 자체적으로 미세조정(Fine-tuning)해 서비스를 개발하는 기업이나 기관들도 참고할 수 있도록 구성됐다.
생성형 AI 서비스가 시장에서 빠르게 확산되고 있는 만큼, 개인정보를 포함한 데이터 처리 기준에 대한 명확한 가이드가 필요하다는 판단에서다.
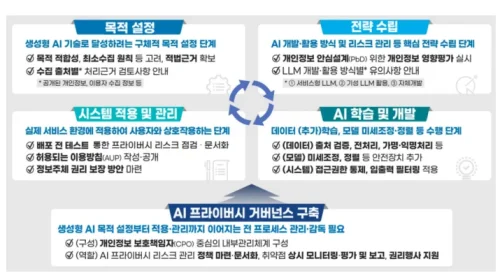
개인정보위원회는 생성형 AI의 개발 및 활용 과정을 △목적 설정 △전략 수립 △AI 학습 및 개발 △시스템 적용 및 관리의 총 4단계로 구분하고, 각 단계별로 최소한의 개인정보 보호 조치를 제시했다.
이 생애주기 기반 접근은 기업들이 기술 적용 맥락에 따라 어떤 법적 기준과 보호 조치를 준수해야 하는지를 보다 쉽게 이해하도록 돕는다.
또한 AI 시스템이 실제로 서비스에 도입되는 방식과 활용 맥락을 유형별로 분석해, 각 유형에 따른 법적 해석과 기술적 안전조치 기준을 함께 제공했다.
개인정보위 고학수 위원장은 “명확한 안내서를 통해 실무 현장의 법적 불확실성이 해소되고, 생성형 AI 개발·활용에 개인정보 보호 관점이 체계적으로 반영될 수 있을 것으로 기대된다”고 말했다.
이어 “앞으로도 개인정보위는 ‘프라이버시’와 ‘혁신’ 두 가치가 상호 공존할 수 있도록 정책 기반을 마련해 나가겠다”고 밝혔다.
이를 통해 생성형 AI를 활용하는 기업들이 시대 변화에 맞춰 안정적인 개인정보 보호 체계를 갖출 수 있도록 한다는 방침이다.
배동현([email protected]) 기사제보
같은 주제 기사 모아보기
IT테크 관련 기사 더 보기










댓글을 남기려면 로그인 해주세요.